| Springboot整合Kafka | 您所在的位置:网站首页 › kafka用法 springboot › Springboot整合Kafka |
Springboot整合Kafka
|
写在前面:各位看到此博客的小伙伴,如有不对的地方请及时通过私信我或者评论此博客的方式指出,以免误人子弟。多谢! 本篇记录一下消息的提交方式,默认的消费位移提交的方式是自动提交的,这个由消费者客户端参数enable.auto.commit控制,默认为true,默认的自动提交不是每消费一条消息就提交一次,而是定期的提交,这个定期的周期时间由客户端参数auto.commit.interval.ms配置,默认为5秒,此参数生效的前提是enable.auto.commit参数为true。自动提交消费位移的方式非常简便,它免去了复杂的位移提交逻辑,让编码更简洁。但随之而来的是重复消费和消息丢失的问题。那重复消费和消息丢失的问题怎么来的呢? 假设当前一次poll()操作拉取的消息为[x+2,x+7],x+2代表上一次提交的消费位移,说明已经完成了x+1前的所有消息的消费,x+5表示当前正在处理的位置。 消息丢失:如果拉取到消息之后就进行了位移提交,即提交了x+8,那么当前消费x+5的时候出现了异常,在故障恢复之后,我们重新拉取的消息是从x+8开始的,也就是说,x+5至x+7之间的消息并未被消费,发生了消息丢失的现象。 消息重复消费:如果位移提交动作是在消费完所有拉取到的消息之后执行的,那么当前消费x+5的时候出现了异常,在故障恢复之后,我们重新拉取的消息是从x+2开始的,也就是说,x+2至x+4之间的消息又重新消费了一遍,发生了消息重复消费的现象。 自动位移提交的方式在正常情况下不会发生消息丢失或重复消费的现象,但是在编程的世界里异常无可避免,与此同时,自动位移提交也无法做到精确的位移管理。在 Kafka中还提供了手动位移提交的方式,这样可以使得开发人员对消费位移的管理控制更加灵活。很多时候并不是说拉取到消息就算消费完成,而是需要将消息写入数据库、写入本地缓存,或者是更加复杂的业务处理。在这些场景下,所有的业务处理完成才能认为消息被成功消费,手动的提交方式可以根据程序的逻辑在合适的地方进行位移提交。开启手动提交功能的前提是消费者客户端参数 enable.auto.commit 配置为false,通过ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG参数配置。 手动提交可以细分为同步提交和异步提交,对应于 KafkaConsumer中的commitSync()和commitAsync()两种类型的方法。 commitSync()方法会根据poll()方法拉取的最新位移来进行提交,只要没有发生不可恢复的错误,它就会阻塞消费者线程直至位移提交完成,不可恢复的错误如:如 CommitFailedException,WakeupException,InterruptException,AuthenticationException uthori zationException 等,我们可以将其捕获并做针对性的处理。 同步提交有四个重载的方法: 1.void commitSync(); 2.void commitSync(Duration timeout); 3.void commitSync(Map offsets); 4.void commitSync(final Map offsets, final Duration timeout); 看下简单示例: @KafkaListener(topics = {"mytest3"},groupId = "test-consumer-group", containerFactory = "batchFactory") public void test(List records, Consumer consumer){ for (ConsumerRecord record:records){ System.out.println(record.topic()); } // 同步提交 consumer.commitAsync(); }如上:对收到的消息简单处理后(此处只是打印了下topic),对整个消息集做同步提交。另外官方示例中还将上面那种方式改为了批量提交,就是定一个数假设为100,对接收的消息每100条提交一次,这两种都有重复消费的问题,假如在业务逻辑处理完之后,并且在同步位移提交前程序出了问题,那么恢复之后只能从上一次位移提交的地方拉取消息,由此在两次位移提交的窗口中出现了重复消费的现象。 对于 采用 commitSync ()的无 参方法 ,它提 交消费位移的频率和拉取批 次消息、处 理批 次消息 的频 率是一样的,如果想寻求更细粒度的、更精准的提交,那么就需要使用 commitSync() 的另一个含参方法---void commitSync(Map offsets);该方法提供了一个 offsets 参数 用来提交指定分区的位移。无参的 commitSync() 方法只能提交当前批次对应的 position值(消费位移)。如果需要提交一个中间值,比如业务每消费一条消息就提交一次位移,那么就可以使用这种方式,看一下代码示例来自《深入理解Kafka_核心设计与实践原理》,以下很多例子都来自此书,直接截图如下:
再贴下《深入理解Kafka_核心设计与实践原理》上的示例代码:
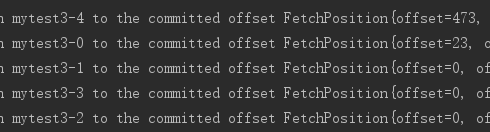
与commitSync()方法相反,异步提交的方式(commitAsync())在执行的时候消费者线程不会阻塞,可能在提交消费位移的结果还未返回之前就开始了新一次的拉取操作,异步提交可使消费者的性能得到一定增强,commitAsync方法有三个不同的重载方法,如下: 1.public void commitAsync() {} 2.public void commitAsync(OffsetCommitCallback callback) {} 3.public void commitAsync(final Map offsets, OffsetCommitCallback callback) {} 看下第二个带回调的方法,当位移提交完成后会回调 OffsetCommitCallback 中的 onComplete() 方法,看下示例代码: /** * 当位移提交完成后会回调 OffsetCommitCallback 中的 onComplete() 方法 * @param records * @param consumer */ @KafkaListener(topics = {"mytest3"},groupId = "test-consumer-group", containerFactory = "batchFactory") public void test(List records, Consumer consumer){ consumer.commitAsync(new OffsetCommitCallback() { @Override public void onComplete(Map offsets, Exception exception) { if(exception == null){ System.out.println("--- offsets ---" + offsets); }else{ log.error("fail to commit offsets {}",offsets,exception); } } }); }commitAsync()提交的时候同样会有失败的情况发生,那么我们应该怎么处理呢?记住千万不要设置重试机制。如果某一次异步提交的消费位移为x但是提交 失败了,然后下一次又异步提交了消费位移为 x+y ,这次成功了。如果这里引入了重试机制,前一次的异步提交的消费位移在重试的时候提交成功了,那么此时的消费位移又变为了x, 如果此时发生异常(或者再均衡) 那么恢复之后的消费者(或者新的消费者)就会从x处开始消费消息,这样就发生了重复消费的问题。 我们可以设置一个递增的序号来维护异步提交的顺序,每次位移提交之后就增加序号相对应的值。在遇到位移提交失败需要重试的时候,可以检查所提交的位移和序号的值的大小, 如果前者小于后者,则说明有更大的位移己经提交了,不需要再进行本次重试:如果两者相同,则说明可以进行重试提交。除非程序编码错误,否则不会出现前者大于后者的情况。 如果位移提交失败的情况经常发生,那么说明系统肯定出现了故障,在-般情况下,位移提交失败的情况很少发生,不重试也没有关系,后面的提交也会有成功的 。 重试会增加代码逻辑的复杂度,不重试会增加重复消费的概率。如果费者异常退出,那么这个重复消费的问题就很难避免,因为这种情况下无法及时提交消费位移, 如果消费者正常退出或发生再均衡的情况,那么可以在退出或再均衡执行之前使用同步提交的方式做最后的把关。 以上记录了这么多,下面记录下手动提交偏移量的使用,主要步骤如下: 消费者配置 configProps.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, “false”);消费者配置ack模式factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);消费者手动提交 consumer.commitSync();顺便看下AckMode的几个枚举值的含义: RECORD:每处理一条commit一次 BATCH(默认):每次poll的时候批量提交一次,频率取决于每次poll的调用频率 TIME:每次间隔ackTime的时间去commit COUNT:累积达到ackCount次的ack去commit COUNT_TIME:ackTime或ackCount哪个条件先满足,就commit MANUAL:listener负责ack,但是背后也是批量上去 MANUAL_IMMEDIATE:listner负责ack,每调用一次,就立即commit 看下代码,首先在消费者配置中配置提交方式为手动方式,并设置ack模式 @Bean public KafkaListenerContainerFactory batchFactory() { ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory(); factory.setConsumerFactory(new DefaultKafkaConsumerFactory(consumerConfigs())); //并发数量 factory.setConcurrency(concurrency); //开启批量监听 factory.setBatchListener(type); // 被过滤的消息将被丢弃 factory.setAckDiscarded(true); // 设置记录筛选策略 factory.setRecordFilterStrategy(new RecordFilterStrategy() { @Override public boolean filter(ConsumerRecord consumerRecord) { String msg = consumerRecord.value().toString(); if(Integer.parseInt(msg.substring(msg.length() - 1)) % 2 == 0){ return false; } // 返回true消息将会被丢弃 return true; } }); // ack模式 factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE); return factory; }监听类中使用commitAsync()提交或者ack方式提交。 @KafkaListener(topics = {"mytest3"},groupId = "test-consumer-group", containerFactory = "batchFactory") public void test(@Payload List message, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic, @Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition, Consumer consumer, Acknowledgment acknowledgment){ System.out.println("接收到的消息:" + message + "---topic:" + topic + "---partition:" + partition); // 提交 consumer.commitAsync(); // ack方式提交 //acknowledgment.acknowledge(); }测试下手动提交是否生效,注释掉上面的提交方法,启动项目,看到mytest3的各分区的offset如下:
访问http://localhost:8080/send15 控制台打印如下:
消息已经发往kafka服务,消费者也已经监听并接收到消息在控制台进行了打印,再次启动服务,看下控制台打印的输出t如下:
可以看到offset并没有变,即没提交offset,并且控制到再次打印了接收到的消息。从以上可知,手动提交生效了。 |





【本文地址】